当前分类:python>>正文
python利用正则表达式过滤超链接
来源:互联网
更新时间:2022年7月2日
现在搞采集的越来越多,要找什么资料都非常的方便,随便翻一下就有了。但是都略有差别,要完全符合自己的要求,还是要改一下。
比如,今天有个朋友要一个过滤超链接的功能,在网上找了找没有想要的,那就自己动手自己写一个吧。
主要过滤什么呢?他的目标是移除他采集过来的超链接,而不是提取源码中的网址。
像下面这种场景的
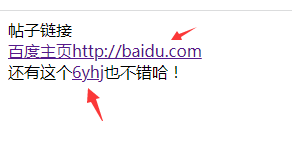
他只要去除超链接,文本保留。
那就可以像我下面这样写罗:
#-*- coding:utf-8 -*-
html='''
<title>大家还做百度搜索排名吗?</title>
帖子链接<a href="https://www.6yhj.com/thread-97327-1-1.html" rel="canonical" >
百度主页http://baidu.com</a>
还有这个<a class='123k' href='https://6yhj.com'>6yhj</a>也不错哈!
'''
import re
pattern=re.compile(r'<a.*?href=.*?>')
content=pattern.sub('',html)
content=content.replace('</a>','')
print(content)
下面是输出的结果:

完全ok的啦!
看到功能实现了,我也就没再研究了,或许还有更简便的方法,或者更简便的写法吧。
本文固定链接:https://6yhj.com/leku-p-2988.html 版权所有,转载请保留本地址!
[猜你喜欢]
标签: